[ML] 회귀 알고리즘 라이브 세션 자료
머신러닝에 관련한 라이브 세션 내용을 실시간으로 정리하면서 들었다.
# 필요한 패키지 임포트
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
# 예제 데이터 생성
np.random.seed(0)
X = np.random.rand(100, 1)
y = 2 + 3 * X + np.random.rand(100, 1)
# 데이터 분할
X_train, X_test, y_train, y_test =
train_test_split(X, y, test_size=0.2, random_state=42)
# 모델 학습
model = LinearRegression()
model.fit(X_train, y_train)
# 예측
y_pred = model.predict(X_test)
# 모델 평가
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Coefficient: {model.coef_[0][0]:.2f}")
print(f"Intercept: {model.intercept_[0]:.2f}")
print(f"Mean squared error: {mse:.2f}")
print(f"R-squared score: {r2:.2f}")
# 결과 시각화
plt.scatter(X_test, y_test, color='blue', label='Actual')
plt.plot(X_test, y_pred, color='red', label='Predicted')
plt.xlabel('X')
plt.ylabel('y')
plt.legend()
plt.show()
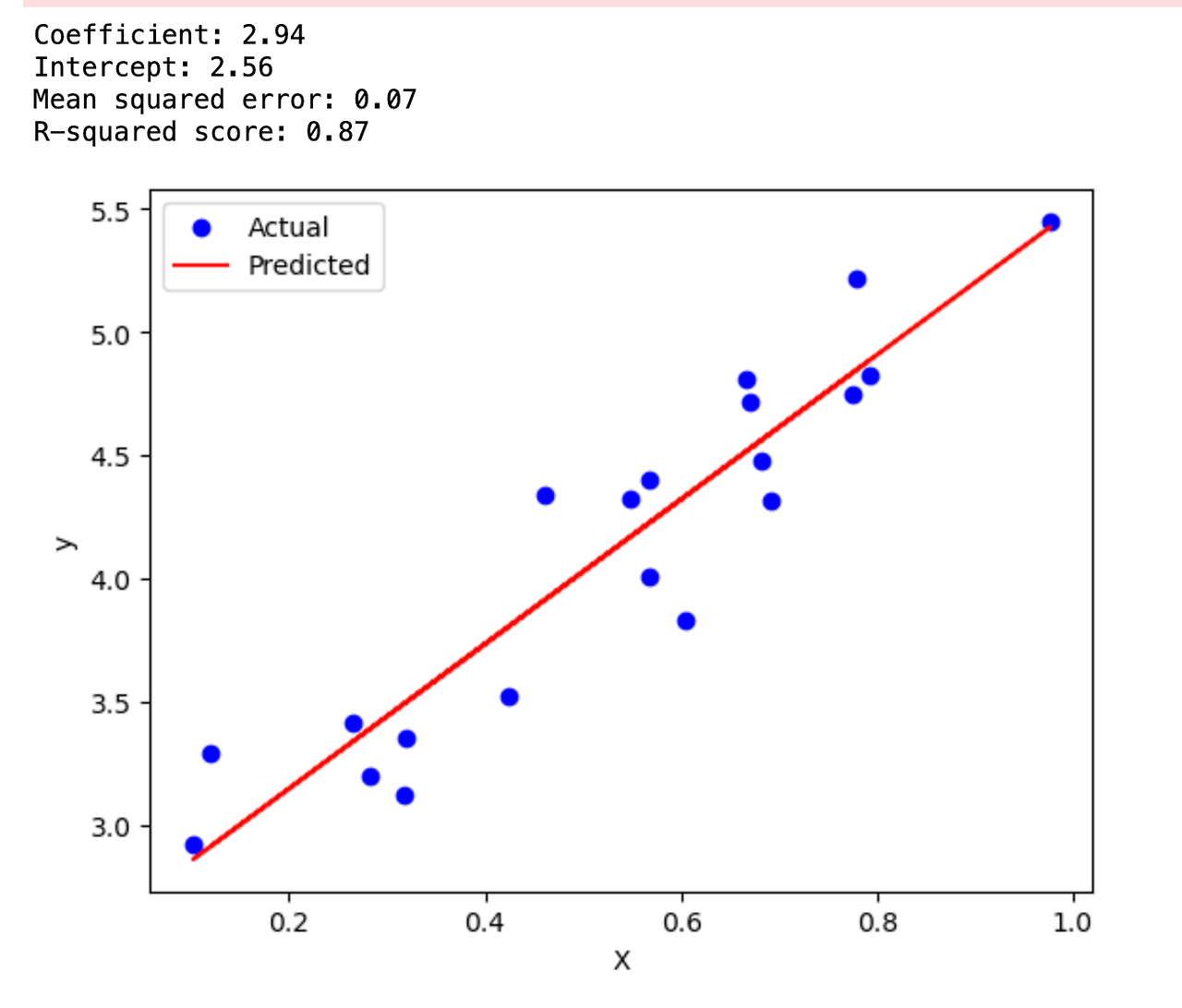
1. 회귀 방정식: y = 2.94x + 2.56
- 기울기(coefficient)가 2.94로, x가 1단위 증가할 때 y는 평균적으로 2.94단위 증가합니다.
- y절편(intercept)은 2.56으로 x가 0일 때 y의 예측값입니다.
* y_train 데이터와 y_test 데이터를 fit해서 예측하는 방정식을 구해낸 것.
2. R-squared 값: 0.87
- 이 모델이 데이터의 변동성을 87% 설명한다는 뜻으로, 상당히 좋은 적합도를 보여줍니다.
3. 평균 제곱 오차(Mean squared error): 0.07
- 예측값과 실제값 간의 차이가 작아 모델의 예측 정확도가 높습니다.
4. 그래프 해석:
- 파란 점들은 실제 데이터를, 빨간 선은 예측 모델을 나타냅니다.
- 대부분의 점들이 예측선 주변에 밀집해 있어 모델이 데이터를 잘 설명하고 있음을 보여줍니다.
결론: 모델은 x와 y 사이의 강한 양의 선형 관계를 잘 포착하고 있으며, 예측 성능도 우수한 것으로 보입니다.
면접에서 많이 물어보는 문제 : MSE, R^2
R Squared
1. 설명력:
- 통계적으로 '설명력'은 독립변수가 종속변수의 변동을 얼마나 잘 설명하는지를 나타냅니다.
- 이는 총 변동(SST) 중 회귀 모델로 설명되는 변동(SSR)의 비율을 의미합니다.
면접에서 잘 물어보기에 외워두면 좋음
2. R-squared (R²):
- 공식: R² = 1 - (SSE / SST) = SSR / SST
- SSE: 오차 제곱합 (Sum of Squared Errors)
- SST: 총 제곱합 (Total Sum of Squares)
- SSR: 회귀 제곱합 (Regression Sum of Squares)
R² = 1 - Σ(y_i - ŷ_i)² / Σ(y_i - ȳ)²
여기서 y_i는 실제값, ŷ_i는 예측값, ȳ는 y의 평균
R-squared 해석:
- R² = 1: 모델이 데이터의 모든 변동을 완벽하게 설명 (이상적인 경우)
- R² = 0: 모델이 데이터의 변동을 전혀 설명하지 못함 (평균으로 예측하는 것과 동일)
- 0 < R² < 1: 모델이 데이터의 일부 변동을 설명함. 값이 클수록 설명력이 높음
주의사항:
1. R-squared는 독립변수가 추가될 때마다 증가하는 경향이 있어, 불필요한 변수 추가를 억제하지 못함
2. 이를 보완하기 위해 Adjusted R-squared를 사용하기도 함
3. R-squared가 높다고 해서 반드시 좋은 모델은 아님. 다른 평가 지표와 함께 고려해야 함
R-squared는 모델의 전반적인 적합도를 평가하는 데 유용하지만,
다른 평가 지표 (예: MSE, RMSE, MAE 등)와 함께 사용하여 모델의 성능을
종합적으로 평가하는 것이 좋습니다.
*x column 수가 늘어날수록 R-Squared 설명력이 높게 나옴. adjust r-squared를 통해 보완하기도 함
MSE (Mean Squared Error)
*이름 잘 외우세요~!
1. 정의:
- MSE는 회귀 모델의 예측 오차를 측정하는 지표입니다.
- 실제값과 예측값 차이의 제곱을 평균한 값입니다.
2. 공식:
MSE = (1/n) * Σ(y_i - ŷ_i)²
여기서 n은 데이터 포인트의 수, y_i는 실제값, ŷ_i는 예측값입니다.
*y_i - y^_i : Error / (1/n) : mean / ^2 : squared 외워둬~
3. 구성 요소:
- 오차 (Error): y_i - ŷ_i (실제값 - 예측값)
- 제곱 오차 (Squared Error): (y_i - ŷ_i)²
- 평균 (Mean): 모든 제곱 오차의 합을 데이터 포인트 수로 나눔
4. MSE 해석:
- MSE = 0: 모델이 데이터를 완벽하게 예측 (이상적인 경우)
- MSE > 0: 값이 작을수록 모델의 예측이 정확함
- 단위는 종속변수의 제곱 단위
5. 특징:
- 항상 비음수 값을 가짐
- 이상치에 민감함 (제곱 때문에 큰 오차가 강조됨)
- 모델 간 비교 시 유용하지만, 절대적인 기준은 아님
6. 관련 지표:
- RMSE (Root Mean Squared Error): MSE의 제곱근 -> 많이 쓰임
- MAE (Mean Absolute Error): 절대 오차의 평균
7. 주의사항:
1. 단위가 제곱되어 있어 직관적인 해석이 어려울 수 있음 -> mse값이 1억이 넘기도 함
2. 이상치에 민감하므로 데이터 전처리가 중요함
3. 다른 데이터셋이나 다른 단위의 모델과 직접 비교하기 어려움 -> 1천원과 1달러처럼 단위가 다른 경우 문제가 생기기도 함. 그래서 Standard Scaler 등을 사용해야함
8. 사용:
- 모델 훈련 과정에서 최소화해야 할 손실 함수로 자주 사용됨
- 모델의 예측 정확도를 평가하는 데 사용됨
- 다른 평가 지표 (R-squared, MAE 등)와 함께 사용하여 종합적인 평가 필요
MSE는 모델의 예측 오차를 직접적으로 측정하는 유용한 지표이지만,
단독으로 사용하기보다는 다른 평가 지표와 함께 사용하여
모델의 성능을 종합적으로 평가하는 것이 좋습니다.
2. 선형회귀를 위한 이상적인 EDA (탐색적 데이터 분석)
EDA는 데이터 분석의 첫 단계로, 데이터의 특성을 이해하고 모델링 전에 필요한 정보를 얻는 과정입니다
- 데이터 품질 확인
- 변수 간 관계 탐색
- 데이터 분포 확인
- 다중공선성 검토
# 보스턴 데이터
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_boston
###보스턴 데이터의 논란!!
###인종차별 논란이 있었다(유독 흑인 여성을 인식하지 못하더라..!, 흑인들이 많이 살면 집 값이 떨어지더라..!)
# 데이터 로드
boston = load_boston()
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df['PRICE'] = boston.target
"""
CRIM: 지역별 1인당 범죄율
ZN: 25,000 평방피트를 초과하는 거주지역의 비율
INDUS: 비소매상업지역 면적 비율
CHAS: 찰스강의 경계에 위치한 경우 1, 아니면 0
NOX: 일산화질소 농도
RM: 주택당 평균 방 개수
AGE: 1940년 이전에 건축된 주택의 비율
DIS: 5개의 보스턴 직업센터까지의 가중평균 거리
RAD: 방사형 고속도로까지의 접근성 지수
TAX: 10,000달러 당 재산세율
PTRATIO: 지역의 교사 대 학생 비율
B: 1000(Bk - 0.63)^2, Bk는 지역의 흑인 비율
LSTAT: 하위 계층의 비율(%)
PRICE: 주택 가격(종속 변수)
"""
#위의 독립 변수를 통해 주택 가격이라는 종속 변수를 확인하는 데이터
# 1. 데이터 품질 확인
print(df.info()) # 데이터 타입 확인
print(df.isnull().sum()) # none 값 체크
#None값 채우는 3가지 방법 1)버리기 / 2)앞의 데이터로 채우기 / 3) medium 갖고 오기
None값을 많이 넣으면 설명력이 부족한 데이터가 됨
날씨 시간 데이터에서 null값이 있는 경우 2)번 채택하는 것이 옳다!
# 2. 변수 간 관계 탐색
"""
df.corr()로 변수 간 상관관계 행렬을 계산합니다.
seaborn의 heatmap으로 상관관계를 시각화합니다.
결과: 변수들 간의 상관관계를 색상으로 표현한 히트맵을 보여줍니다.
"""
correlation_matrix = df.corr()
plt.figure(figsize=(12, 10))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm')
plt.title('Correlation Heatmap')
plt.show()
# 3. 데이터 분포 확인
"""
모든 변수에 대해 히스토그램과 KDE(커널 밀도 추정) 플롯을 그립니다.
4x4 그리드에 각 변수의 분포를 시각화합니다.
결과: 각 변수의 분포 형태를 확인할 수 있습니다.
(KDE : 확률 밀도 함수를 추정하는 비모수적 방법)
"""
plt.figure(figsize=(12, 10))
for i, column in enumerate(df.columns):
plt.subplot(4, 4, i+1)
sns.histplot(df[column], kde=True)
plt.title(column)
plt.tight_layout()
plt.show()
# 4. 다중공선성 검토
"""
VIF(Variance Inflation Factor)를 계산하여 다중공선성을 평가합니다.
'PRICE'를 제외한 모든 변수에 대해 VIF를 계산합니다.
결과: 각 독립변수의 VIF 값을 출력합니다. 높은 VIF 값은 다중공선성을 나타냅니다.
"""
from statsmodels.stats.outliers_influence import variance_inflation_factor
def calculate_vif(X):
vif = pd.DataFrame()
vif["variables"] = X.columns
vif["VIF"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
return vif
X = df.drop('PRICE', axis=1)
vif_data = calculate_vif(X)
print(vif_data)
# 종속변수와 독립변수들의 산점도
"""
'PRICE'(종속변수)와 각 독립변수 간의 산점도를 그립니다.
3x5 그리드에 각 독립변수와 PRICE의 관계를 시각화합니다.
결과: 각 독립변수와 PRICE 간의 관계를 산점도로 보여줍니다.
"""
fig, axes = plt.subplots(3, 5, figsize=(20, 15))
axes = axes.ravel()
for i, column in enumerate(X.columns):
sns.scatterplot(data=df, x=column, y='PRICE', ax=axes[i])
plt.tight_layout()
plt.show()
2. 변수 간 관계 탐색
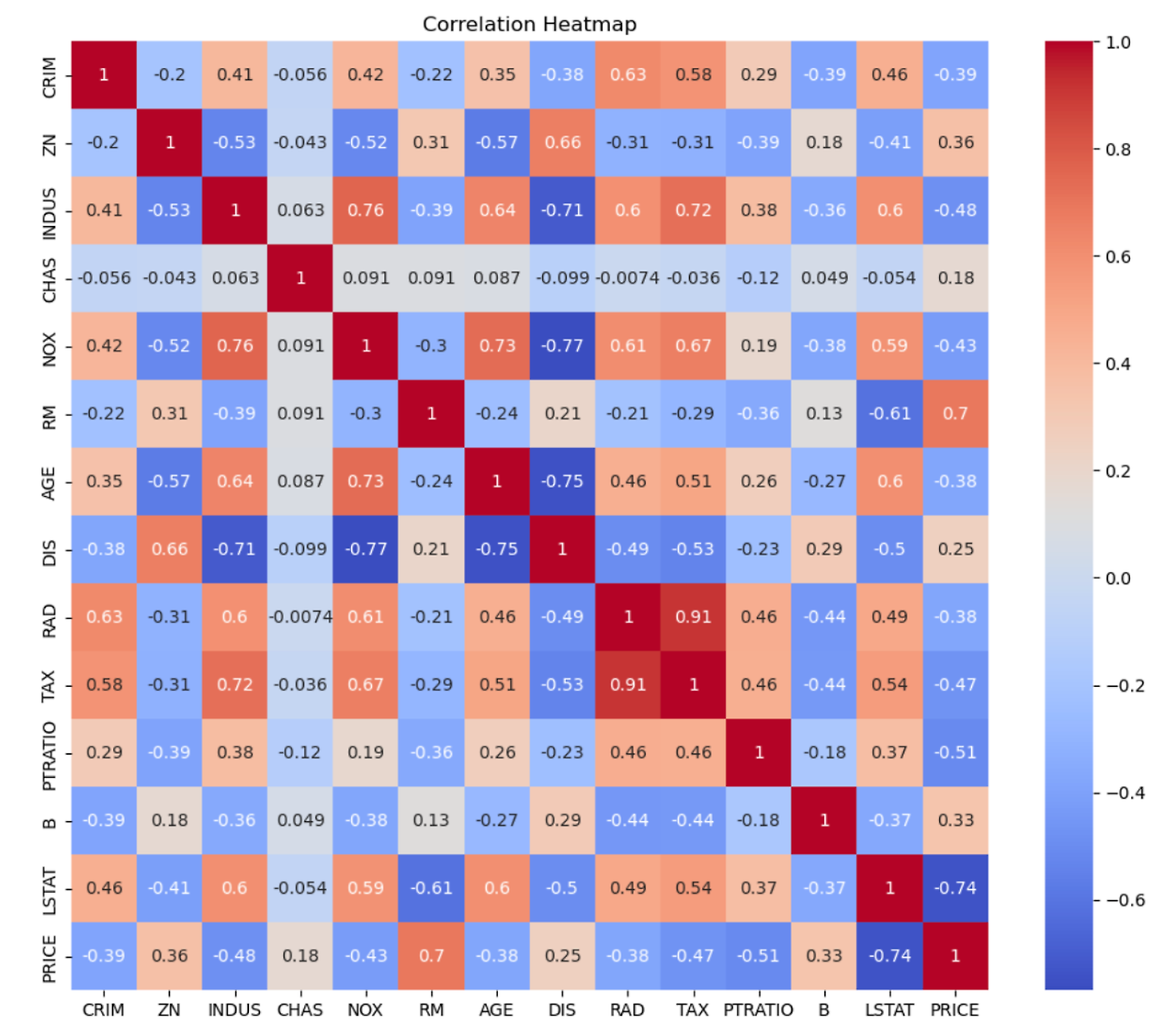
음, 양의 상관 관계를 한 눈에 보고 분석하기 좋다.
3. 데이터 분포 확인 > 변환 시키기
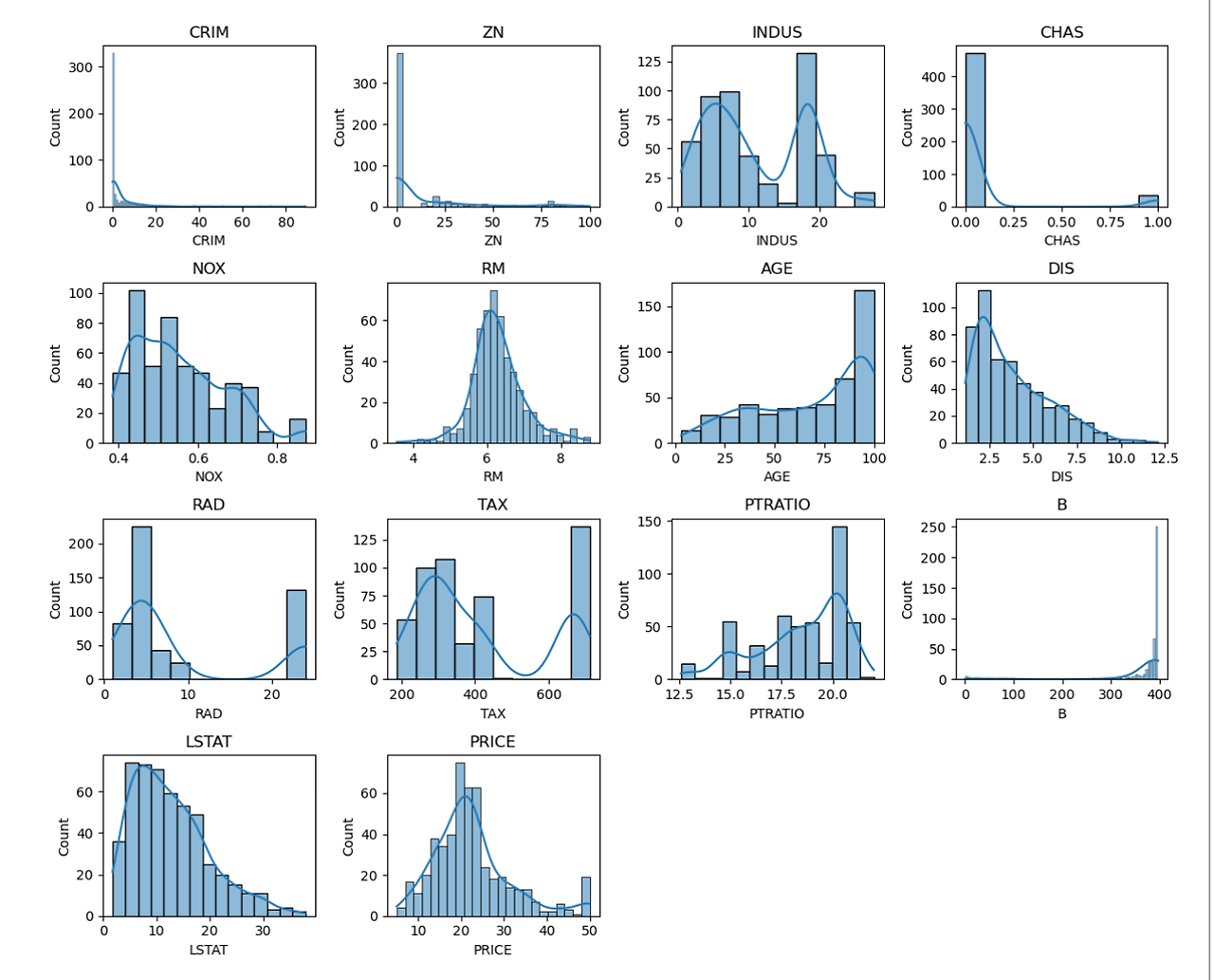
- 전처리 레시피
- CRIM: 로그 변환
- 매우 왼쪽으로 치우친 분포를 보이므로 로그 변환이 적합합니다.
- ZN: 로그 변환 또는 제곱근 변환
- 0 근처에 많은 값이 몰려있어 로그 변환이 효과적일 수 있습니다.
- INDUS: 특별한 변환 불필요
- 비교적 균형 잡힌 분포를 보입니다.
- CHAS: 이진 변수로 보이므로 변환 불필요
- NOX: Yeo-Johnson 변환
- 약간의 왜도가 있으므로 Yeo-Johnson 변환을 고려할 수 있습니다.
- RM: 특별한 변환 불필요
- 정규 분포에 가까운 모습입니다.
- AGE: RobustScaler
- 오른쪽으로 약간 치우쳐 있어 RobustScaler를 적용할 수 있습니다.
- DIS: 약한 로그 변환 또는 제곱근 변환
- 오른쪽으로 약간 치우친 분포를 보입니다.
- RAD: 제곱근 변환 또는 로그 변환
- 이산적인 값들이 보이므로 제곱근 변환이 적절할 수 있습니다.
- TAX: 특별한 변환 불필요
- 비교적 균형 잡힌 분포를 보입니다.
- PTRATIO: 특별한 변환 불필요
- 정규 분포에 가까운 모습입니다.
- B: 윈저화 (Winsorization)
- 극단적인 아웃라이어가 있어 윈저화를 적용할 수 있습니다.
- LSTAT: 약한 로그 변환
- 오른쪽으로 약간 치우친 분포를 보입니다.
- PRICE: 특별한 변환 불필요
- 비교적 균형 잡힌 분포를 보입니다.
- CRIM: 로그 변환
df['CRIM_log'] = np.log1p(df['CRIM'])
df['ZN_log'] = np.log1p(df['ZN'])df['RAD_sqrt'] = np.sqrt(df['RAD'])from scipy import stats
df['LSTAT_boxcox'], _ = stats.boxcox(df['LSTAT'])from sklearn.preprocessing import PowerTransformer
pt = PowerTransformer(method='yeo-johnson')
df['NOX_yeojohnson'] = pt.fit_transform(df[['NOX']])from scipy.stats import mstats
df['B_winsor'] = mstats.winsorize(df['B'], limits=[0.05, 0.05])from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
df['AGE_robust'] = scaler.fit_transform(df[['AGE']])4. 다중공선성 검사
VIF란? : 다중 공선성 측정하는 통계적 방법
1. VIF의 정의:
VIF = 1 / (1 - R²)
여기서 R²은 해당 변수를 다른 모든 독립변수로 회귀분석했을 때의 결정계수입니다.
2. 계산 과정:
a. 한 독립변수를 선택하여 종속변수로 설정합니다.
b. 나머지 독립변수들을 사용하여 회귀분석을 수행합니다.
c. 이 회귀분석의 R²을 구합니다.
d. VIF = 1 / (1 - R²) 공식을 적용합니다.
e. 모든 독립변수에 대해 이 과정을 반복합니다.
3. 해석:
- VIF = 1: 다중공선성 없음
- VIF > 1: 변수들 간 상관관계 존재
- 일반적으로 VIF > 5 또는 10: 심각한 다중공선성 의심
4. 의미:
- VIF는 다른 변수들과의 상관관계로 인해 해당 변수의 분산이 얼마나 "팽창"되었는지 나타냅니다.
- 높은 VIF는 해당 변수가 다른 변수들과 강한 선형관계를 가짐을 의미합니다.
5. 예시:
VIF가 4인 경우, 해당 변수의 표준오차가 다중공선성이 없을 때보다 2배(√4) 커졌다는 뜻입니다.
* 독립성이 없는 변수들을 제거하기 위해!
근데 현업에서 VIF가 5이상 나오는 경우가 많음. 그래서 도메인에 따라서 심각한 다중공선성이 우려되어도 채택되는 경우가 있음.
5. 종속변수와 독립변수들의 산점도
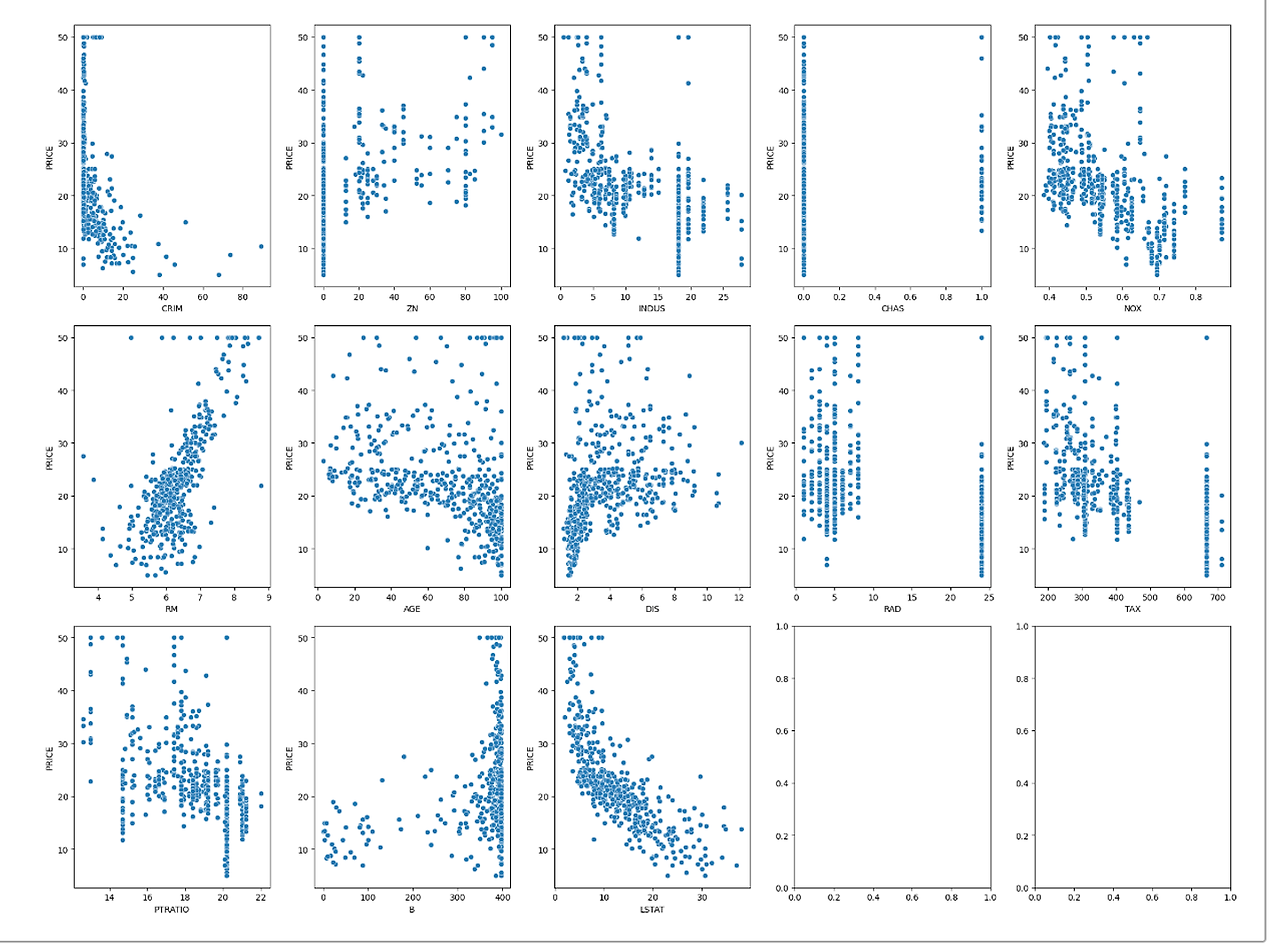
6, 13번째 같은 경우 선이 꽤 잘 그려질 것 같이 생겼으므로 이 변수들을 중점적으로 분석하게 됨
3. 선형회귀 모델링
씨앗 모델, 베이스 모델을 세워두고 이것보다 더 좋은 결과를 찾아나가는 방법도 있다!
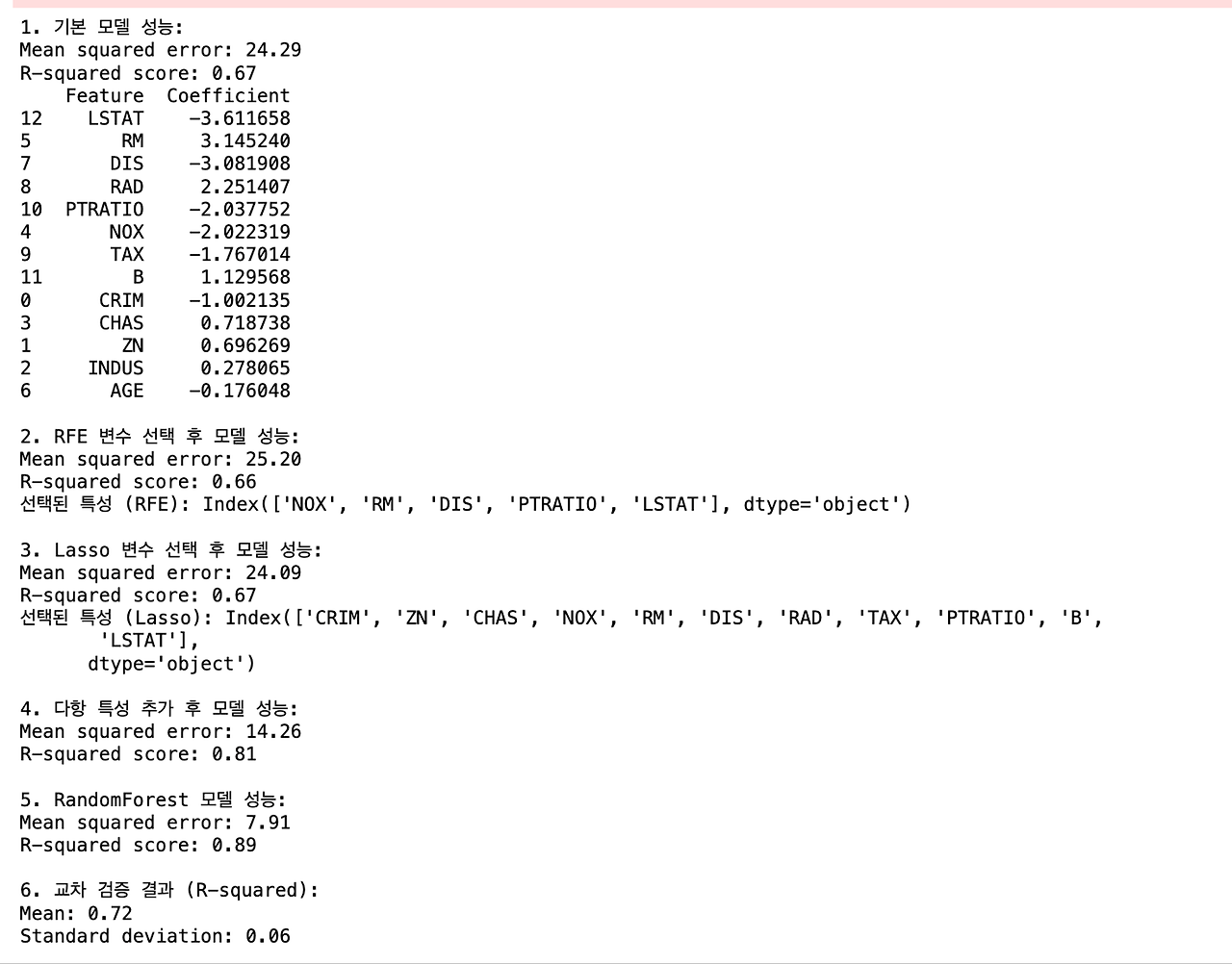
1. 기본 선형회귀 모델: 이 모델은 기준점으로 사용되며, 다른 모델들과 비교하기 위한 베이스라인입니다.
2. RFE (Recursive Feature Elimination) 방식:
- 방법: RFE는 반복적으로 특성의 중요도를 평가하고 가장 중요하지 않은 특성을 제거하는 과정을 거칩니다.
- 성능 향상 이유: a) 불필요한 특성을 제거하여 모델의 복잡성을 줄입니다. b) 가장 중요한 특성만을 선택하여 노이즈를 줄이고 모델의 일반화 능력을 향상시킵니다. c) 오버피팅 위험을 감소시킵니다.
*데이터가 별로 없고, 컬럼이 별로 없는 경우는 효과적이지 않을 수 있다
3. Lasso를 사용한 특성 선택:
- 방법: Lasso 회귀는 L1 정규화를 사용하여 덜 중요한 특성의 계수를 0으로 만듭니다.
- 성능 향상 이유: a) 자동으로 특성 선택을 수행하여 중요한 특성만 남깁니다. b) 모델의 복잡성을 줄이고 해석 가능성을 높입니다. c) 다중공선성 문제를 해결하는 데 도움이 됩니다.
*군집합 프로젝트 할 때 많이 다뤄주실 거임.
4. 다항 특성 추가:
- 방법: 기존 특성들의 2차항과 상호작용항을 추가합니다.
- 성능 향상 이유: a) 비선형 관계를 포착할 수 있어 모델의 표현력이 증가합니다. b) 특성 간의 상호작용을 고려할 수 있습니다. c) 복잡한 패턴을 학습할 수 있어 더 정확한 예측이 가능합니다.
*다항함수가 들어가는 순간 과적합의 문제가 커짐 / 쎈수학을 풀고 수능에 응시하는 것과 기출만 풀고 수능에 응시한 것의 차이. 기출만 푼 사람이 이번 수능에는 잘 볼 수도 있지만 기본 개념이 부족할 수도 있다.
5. RandomForest 사용:
- 방법: 여러 개의 결정 트리를 생성하고 그 결과를 평균내는 앙상블 기법입니다.
- 성능 향상 이유: a) 비선형 관계를 잘 포착할 수 있습니다. b) 특성 간 상호작용을 자동으로 고려합니다. c) 앙상블 효과로 인해 과적합을 줄이고 일반화 성능이 향상됩니다. d) 이상치에 강건합니다.
*여러번 테스트를 해서 평균을 내는 기법이다 보니, a) b) c) d)의 이유가 나옴
다항 특성 추가의 장점과 다른 모델의 장점을 합친 모델. 평균적인 성능이 좋음
하지만... 계산 속도가 느림
6. 교차 검증:
- 방법: 데이터를 여러 부분으로 나누어 반복적으로 학습과 검증을 수행합니다.
- 성능 향상 이유: a) 모델의 일반화 성능을 더 정확하게 추정할 수 있습니다. b) 과적합 여부를 판단하는 데 도움이 됩니다. c) 데이터 분할에 따른 편향을 줄일 수 있습니다.
* 즉, standard scaler 넣어서 베이스 모델 만들고
2, 3, 4, 5 등등 다른 모델들을 적용해봄으로써
(효과가 적은) 전처리 과정을 생략하고 효율적으로 성능이 좋은 모델, 목표를 설정할 수 있다.
물론 이후에 전처리 과정은 필수적이다.
이 모든 과정을 거치면서, 이 모델은 이러한 장점이 있고 저러한 단점이 있는데 이 사안에 대해서는 이게 중요하기 때문에 이 모델을 최종적으로 선정하게 되었다! 라는 논리를 가지고 프로젝트를 끝내는 것이 중요하다.
더보기란엔 여러 모델을 실행하는 코드가 적혀있다.
import numpy as np
import pandas as pd
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.linear_model import LinearRegression, Lasso, ElasticNet
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.preprocessing import StandardScaler, PolynomialFeatures
from sklearn.feature_selection import SelectFromModel, RFE
from sklearn.pipeline import Pipeline
# 데이터 로드 및 전처리
boston = load_boston()
X = pd.DataFrame(boston.data, columns=boston.feature_names)
y = boston.target
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 스케일링
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 1. 기본 선형회귀 모델
model = LinearRegression()
model.fit(X_train_scaled, y_train)
y_pred = model.predict(X_test_scaled)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("1. 기본 모델 성능:")
print(f"Mean squared error: {mse:.2f}")
print(f"R-squared score: {r2:.2f}")
# 계수 확인
coefficients = pd.DataFrame({'Feature': X.columns, 'Coefficient': model.coef_})
print(coefficients.sort_values(by='Coefficient', key=abs, ascending=False))
# 2. 기존 RFE 방식
selector_rfe = RFE(estimator=LinearRegression(), n_features_to_select=5, step=1)
selector_rfe = selector_rfe.fit(X_train_scaled, y_train)
X_train_selected_rfe = X_train_scaled[:, selector_rfe.support_]
X_test_selected_rfe = X_test_scaled[:, selector_rfe.support_]
model_selected_rfe = LinearRegression()
model_selected_rfe.fit(X_train_selected_rfe, y_train)
y_pred_selected_rfe = model_selected_rfe.predict(X_test_selected_rfe)
mse_selected_rfe = mean_squared_error(y_test, y_pred_selected_rfe)
r2_selected_rfe = r2_score(y_test, y_pred_selected_rfe)
print("\n2. RFE 변수 선택 후 모델 성능:")
print(f"Mean squared error: {mse_selected_rfe:.2f}")
print(f"R-squared score: {r2_selected_rfe:.2f}")
print("선택된 특성 (RFE):", X.columns[selector_rfe.support_])
# 3. Lasso를 사용한 특성 선택
lasso = Lasso(alpha=0.1)
selector_lasso = SelectFromModel(lasso, prefit=False)
selector_lasso.fit(X_train_scaled, y_train)
X_train_selected_lasso = selector_lasso.transform(X_train_scaled)
X_test_selected_lasso = selector_lasso.transform(X_test_scaled)
model_selected_lasso = LinearRegression()
model_selected_lasso.fit(X_train_selected_lasso, y_train)
y_pred_selected_lasso = model_selected_lasso.predict(X_test_selected_lasso)
mse_selected_lasso = mean_squared_error(y_test, y_pred_selected_lasso)
r2_selected_lasso = r2_score(y_test, y_pred_selected_lasso)
print("\n3. Lasso 변수 선택 후 모델 성능:")
print(f"Mean squared error: {mse_selected_lasso:.2f}")
print(f"R-squared score: {r2_selected_lasso:.2f}")
print("선택된 특성 (Lasso):", X.columns[selector_lasso.get_support()])
# 4. 다항 특성 추가
poly = PolynomialFeatures(degree=2, include_bias=False)
X_train_poly = poly.fit_transform(X_train_scaled)
X_test_poly = poly.transform(X_test_scaled)
model_poly = LinearRegression()
model_poly.fit(X_train_poly, y_train)
y_pred_poly = model_poly.predict(X_test_poly)
mse_poly = mean_squared_error(y_test, y_pred_poly)
r2_poly = r2_score(y_test, y_pred_poly)
print("\n4. 다항 특성 추가 후 모델 성능:")
print(f"Mean squared error: {mse_poly:.2f}")
print(f"R-squared score: {r2_poly:.2f}")
# 5. RandomForest 사용
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
rf_model.fit(X_train_scaled, y_train)
y_pred_rf = rf_model.predict(X_test_scaled)
mse_rf = mean_squared_error(y_test, y_pred_rf)
r2_rf = r2_score(y_test, y_pred_rf)
print("\n5. RandomForest 모델 성능:")
print(f"Mean squared error: {mse_rf:.2f}")
print(f"R-squared score: {r2_rf:.2f}")
# 6. 교차 검증
cv_scores = cross_val_score(model, X_train_scaled, y_train, cv=5, scoring='r2')
print("\n6. 교차 검증 결과 (R-squared):")
print(f"Mean: {cv_scores.mean():.2f}")
print(f"Standard deviation: {cv_scores.std():.2f}")중요 포인트
1.
y값은 도달점이기 때문에 어떠한 경우에도 조작하면 안된다!
standard scaler를 넣거나 하면 안된다!
2.
x_Train 데이터에서 한 전처리는 그대로 똑같이 x_Test 데이터에서 적용해야한다.