과제가 제출 기한 30분 전에 소실되다... / 과제 복기
ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
정오부터 이 상태다... 정신이...
어이가 없음...

일단 약 3일에 걸쳐서 과제를 수행했다.
머신러닝! 이름부터 어렵잖은가.
강의를 잘 못 듣는 나는 이 과제를 도약지로 삼아 성장하고자 했다.
실제로 기초 프로젝트 때 가장 성장했었고 문제가 주어질 때 배우는 게 많은 타입이기에.
근데, 제출하기 1시간 전에 파일을 저장하는 과정에서 확장자명을 입력하지 않아
저장은 되지 않고 내용은 다시 안불러와지는 문제가 발생했다.
vscode 오른쪽 아래에 다시 시도하기 팝업이 뜨긴 했는데
다시 저장하지뭐 하고 취소를 눌러버렸다.
사실 다시 시도해도 확장자명을 적지 않은 게 확실했어서 해당 팝업 버튼을 눌렀어도 결과는 같았을 것이다.
당황해서 튜터분들께도 질문했으나 역시나 방법은 없었다.
이미 컨트롤제트나 최근 항목 불러오기, 닫은 파일 열기 등 다 해봤기 때문이다.
실제로 닫힌 편집기 열기를 했더니 그 전에 작업하던 파일이 열리긴 했다.
근데, 파일만 열렸다. 저장은 안된 채로... ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
아 어이가 없네 ㅋㅋㅋㅋ
아무튼 과제를 빈칸으로 제출할 수는 없어서 얼른 뤼튼으로 적어서 냈다...
일단 튜터분들께 죄송하기도 하고
내가 수시간을 정리해온 게 사라지니까 마음이 너무 속상했다.
Markdown으로 엄청 상세히 적어서 제출했는데...!
이거 블로그에 정리할 생각에 설렜을 정도다...
참...
아무튼 과제 복기를 시작하자면
과제의 간단한 요약은 이렇다.
1. 데이터셋 불러오기
2. Diabetes 데이터 회귀 분석 진행하기
3. iris데이터 DecisionTree로 분류
4. 타이타닉 데이터 불러오기 및 전처리하기
5. 타이타닉 데이터 분류하기
6. iris 데이터를 이용하여 클러스터링을 수행하고 시각화 하세요
1-6번까지의 과제 중 1-3번은 베이직, 4-6번은 챌린지 문제가 딸려있는 과정이었다.
챗지피티가 금지되어 있어서 하나하나 내 손으로 하기 위해 강의창과 강의자료를 모두 띄워두었다.
데이터셋 불러올 때부터 문제가 생겨서 꽤 오랜 시간을 허비했던 것 같다.
그런 점에서 chatgpt 사용이 코딩 능력에 독이 된다는 것은 백번 맞는 말이다.
좌충우돌 여러가지 시도들을 한 흔적은 유실되어 날아갔지만
대강 기억 나는 것들과 개념들, 그리고 도움 받은 블로그들에서
내 과제를 다시 복기하여 아래에 정리해두겠다.
우선, 가장 좋았던 코드부터
import warnings
warnings.filterwarnings(action='ignore')
과제로 여러가지 시도를 하다보면 쓸데없는(?) 경고들이 많이 나오는데
이 코드를 통해 전부 무시할 수 있다.
1번
1번 문제부터 diabetes 데이터셋을 가져오기로 했다. 계속 예제로 사용하던 titanic 데이터와는 다르게
당뇨병의 진행 정도를 나타내는 연속형 'target' 데이터가 따로 존재하기 때문에
이 두 가지 데이터를 한 가지 데이터 프레임으로 결합해주는 작업이 필요했다. (물론 결합하지 않고도 가능하다)
from sklearn.datasets import load_diabetes
diabetes = load_diabetes()
X, y = diabetes.data, diabetes.target
데이터를 불러오는 코드
import pandas as pd
from sklearn.datasets import load_diabetes
diabetes = load_diabetes()
diabetes_df = pd.DataFrame(data=diabetes.data, columns=diabetes.feature_names)
diabetes_df['target'] = diabetes.target
print(diabetes_df.head(3))
print(diabetes_df.info())
마찬가지로 데이터를 불러오는 코드지만
데이터프레임화와 함께 target데이터를 diabetes_df에 추가하는 작업을 더했다.
이후 데이터프레임의 개괄을 보기위해 head, info를 출력했다
2번
diabetes 데이터를 가지고 해당 데이터의 특징을 정리하고 선형회귀, 다항회귀를 진행 후 MSE를 통해 성능을 계산하는 문제이다.
Accuracy를 이 데이터에서 구할 수 있는지에 대한 해답도 적어야 했다.
우선
age sex bmi bp s1 s2 s3
0 0.038076 0.050680 0.061696 0.021872 -0.044223 -0.034821 -0.043401
1 -0.001882 -0.044642 -0.051474 -0.026328 -0.008449 -0.019163 0.074412
2 0.085299 0.050680 0.044451 -0.005670 -0.045599 -0.034194 -0.032356
s4 s5 s6 target
0 -0.002592 0.019907 -0.017646 151.0
1 -0.039493 -0.068332 -0.092204 75.0
2 -0.002592 0.002861 -0.025930 141.0
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 442 entries, 0 to 441
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 age 442 non-null float64
1 sex 442 non-null float64
2 bmi 442 non-null float64
3 bp 442 non-null float64
4 s1 442 non-null float64
5 s2 442 non-null float64
6 s3 442 non-null float64
7 s4 442 non-null float64
8 s5 442 non-null float64
9 s6 442 non-null float64
10 target 442 non-null float64
dtypes: float64(11)
memory usage: 38.1 KB
None
기존의 10개의 컬럼뿐만 아니라 target 컬럼이 새로 생긴 걸 볼 수 있고,
모든 행이 non-null 값이며
컬럼명(특징, 입력 변수)은 아래의 순서대로 이루어져 있다.
- 나이
- 성별
- BMI 신체 질량 지수
- 평균 혈압
- s1 tc, 총 혈청 콜레스테롤
- s2 ldl, 저밀도지단백질
- s3 hdl, 고밀도 지단백질
- s4 tch, 총 콜레스테롤 / HDL
- s5 ltg, 혈청 트리글리세리드 수치의 log
- s6 글루, 혈당 수치
해당 특징들이 당뇨병의 진행 상황을 어느정도 예측하는지를 알아보는 것이 이 데이터셋의 목표이다.
여기서 target 데이터인 당뇨의 진행 정도는 연속형 데이터이다.
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.metrics import mean_squared_error
X = diabetes.data
y = diabetes.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
train_test_split 함수를 사용하여 데이터를 train 세트와 test 세트로 나눈다.
test_size = 0.3은 전체 데이터의 30%를 테스트 세트로 사용하겠단 의미이며
random_state=42 는 랜덤하게 표본을 추출하겠다는 의미이다. -> 데이터 분류 시 재현성을 보장할 수 있다.
X_train과 y_train은 학습에 사용되며, X_test와 y_test는 모델 평가에 사용된다.
선형회귀
linear_model = LinearRegression()
linear_model.fit(X_train, y_train)
y_pred_linear = linear_model.predict(X_test)
mse_linear = mean_squared_error(y_test, y_pred_linear)
print(f"Linear Regression MSE: {mse_linear:.2f}")
Linear Regression MSE: 2821.75
LinearRegression 클래스의 인스턴스를 생성하여 linear_model 변수에 저장한다.
fit 메서드를 사용하여 X_train과 y_train 데이터를 기반으로 선형 회귀 모델을 학습시킨다.
이 과정에서 모델은 입력 특성과 타겟 값 간의 관계를 학습한다.
학습된 선형 회귀 모델을 사용하여 X_test에 대한 예측을 수행하고, 예측한 값을 y_pred_linear 변수에 저장한다. 이 값은 테스트 데이터에 대한 linear_model의 예측 결과
mean_squared_error 함수를 사용하여 실제 타겟 값인 y_test와 모델의 예측 값인 y_pred_linear 간의 평균 제곱 오차(MSE)를 계산한다. 이 값은 모델의 성능을 평가하는 지표로 사용된다.
출력값은 2821.75로 나왔다.
다항회귀
poly = PolynomialFeatures(degree=2)
X_train_poly = poly.fit_transform(X_train)
X_test_poly = poly.transform(X_test)
poly_model = LinearRegression()
poly_model.fit(X_train_poly, y_train)
y_pred_poly = poly_model.predict(X_test_poly)
mse_poly = mean_squared_error(y_test, y_pred_poly)
print(f"Polynomial Regression MSE: {mse_poly:.2f}")
- PolynomialFeatures 클래스를 사용하여 차수가 2인 다항식 변환기를 생성한다. 이 변환기는 입력 특성의 다항식 조합을 생성하는 데 사용된다.
- fit_transform 메서드를 사용하여 X_train 데이터를 다항식 형태로 변환하고, 변환된 데이터를 X_train_poly 변수에 저장한다. 이 과정에서 원래의 특성 외에도 모든 조합의 차수 2 항이 추가된다.
- transform 메서드를 사용하여 X_test 데이터를 다항식 형태로 변환하고, 변환된 데이터를 X_test_poly 변수에 저장한다. fit_transform과 달리 테스트 데이터는 훈련 데이터에 사용된 변환기를 그대로 적용한다.
- 새로운 선형 회귀 모델 인스턴스를 생성하여 poly_model 변수에 저장한다. 이 모델은 다항식 특성을 기반으로 학습된다.
- 다항식 변환된 훈련 데이터 X_train_poly와 타겟 값 y_train을 사용하여 다항 회귀 모델을 학습시킨다.
- 학습된 다항 회귀 모델을 사용하여 X_test_poly에 대한 예측을 수행하고, 예측한 값을 y_pred_poly 변수에 저장한다.
- mean_squared_error 함수를 사용하여 실제 타겟 값인 y_test와 다항 회귀 모델의 예측 값인 y_pred_poly 간의 평균 제곱 오차(MSE)를 계산한다.
- 계산된 다항 회귀 모델의 MSE 값을 포맷팅하여 출력한다.
해당 부분은 설명하기가 어려워서 뤼튼에 정리를 부탁했다.
아래 접은 글에서 다항식 변환기가 하는 정확한 역할에 대해 확인할 수 있다.
차수가 2인 다항식 변환기를 생성하는 이유는 모델이 비선형 관계를 더 잘 학습할 수 있도록 하기 위함입니다. 선형 회귀는 입력 특성과 타겟 값 간의 선형 관계를 가정하지만, 실제 데이터에서는 비선형 관계가 존재할 수 있습니다. 다항식 변환을 통해 이러한 비선형 관계를 모델링할 수 있습니다.
다항식 조합 예시
예를 들어, 두 개의 특성 (x_1)과 (x_2)가 있을 때, 차수가 2인 다항식 변환기를 사용하면 다음과 같은 조합이 생성됩니다:
- 원래 특성:
- (x_1)
- (x_2)
- 차수 2 조합:
- (x_1^2) (첫 번째 특성의 제곱)
- (x_2^2) (두 번째 특성의 제곱)
- (x_1 \cdot x_2) (두 특성의 곱)
이렇게 변환된 특성들을 사용하면, 모델은 다음과 같은 형태의 회귀 방정식을 학습할 수 있습니다:
[ y = b_0 + b_1 x_1 + b_2 x_2 + b_3 x_1^2 + b_4 x_2^2 + b_5 (x_1 \cdot x_2) ]
여기서 (b_0, b_1, b_2, b_3, b_4, b_5)는 모델이 학습하는 계수들입니다.
비선형 관계 예시
예를 들어, 실제 데이터에서 (y)가 (x_1)과 (x_2)의 곱에 비례한다고 가정해 보겠습니다:
[ y = 2 + 3x_1 + 4x_2 + 5(x_1 \cdot x_2) ]
이 경우, 단순 선형 회귀 모델로는 이 관계를 잘 설명할 수 없지만, 다항식 변환을 통해 (x_1)과 (x_2)의 곱을 추가하면 모델이 이 비선형 관계를 학습할 수 있게 됩니다.
결론적으로, 차수가 2인 다항식 변환기를 통해 모델의 표현력을 높이고, 데이터의 비선형 관계를 효과적으로 모델링할 수 있습니다.
차수가 3인 다항식 변환기를 사용하면, 원래의 특성에서 더 많은 조합을 생성할 수 있어 모델이 더욱 복잡한 비선형 관계를 학습할 수 있습니다. 두 개의 특성 (x_1)과 (x_2)가 있을 때, 차수가 3인 다항식 변환기를 적용하면 다음과 같은 조합이 생성됩니다.
차수가 3인 다항식 조합
- 원래 특성:
- (x_1)
- (x_2)
- 차수 1 조합 (원래 특성):
- (x_1)
- (x_2)
- 차수 2 조합 (제곱 항):
- (x_1^2) (첫 번째 특성의 제곱)
- (x_2^2) (두 번째 특성의 제곱)
- (x_1 \cdot x_2) (두 특성의 곱)
- 차수 3 조합 (세제곱 항):
- (x_1^3) (첫 번째 특성의 세제곱)
- (x_2^3) (두 번째 특성의 세제곱)
- (x_1^2 \cdot x_2) (첫 번째 특성의 제곱과 두 번째 특성의 곱)
- (x_1 \cdot x_2^2) (첫 번째 특성과 두 번째 특성의 제곱의 곱)
변환된 특성 목록
따라서, 차수가 3인 다항식 변환기를 사용하면 다음과 같은 특성들이 생성됩니다:
- (x_1)
- (x_2)
- (x_1^2)
- (x_2^2)
- (x_1 \cdot x_2)
- (x_1^3)
- (x_2^3)
- (x_1^2 \cdot x_2)
- (x_1 \cdot x_2^2)
회귀 모델의 형태
이렇게 변환된 특성들을 사용하면, 모델은 다음과 같은 형태의 회귀 방정식을 학습할 수 있습니다:
[ y = b_0 + b_1 x_1 + b_2 x_2 + b_3 x_1^2 + b_4 x_2^2 + b_5 (x_1 \cdot x_2) + b_6 x_1^3 + b_7 x_2^3 + b_8 (x_1^2 \cdot x_2) + b_9 (x_1 \cdot x_2^2) ]
이 방정식에서는 모델이 더 많은 비선형 관계를 포착할 수 있는 가능성이 높아집니다. 예를 들어, (y)가 (x_1)과 (x_2)의 세제곱 항이나 두 특성을 조합한 복잡한 형태로 나타날 수 있습니다.
비선형 관계 예시
예를 들어, 데이터가 다음과 같은 관계를 가진다고 가정해 보겠습니다:
[ y = 2 + 3x_1 + 4x_2 + 5(x_1 \cdot x_2) + 6x_1^2 + 7x_2^2 + 8x_1^3 + 9x_2^3 ]
이와 같이 차수가 3인 다항식 변환기를 사용하면, 모델이 더욱 복잡한 관계를 학습할 수 있게 되므로, 실제 데이터의 패턴을 더 잘 포착할 가능성이 높아집니다.
Polynomial Regression MSE: 3168.93
선형회귀 MSE 값이 다항회귀 MSE 값보다 낮으므로 해당 모델에서는 선형회귀가 더 예측을 잘 했다고 볼 수 있다.
Accuracy
한편 Accuracy는 분류 문제에서 모델의 예측이 얼마나 정확한지를 나타내는 지표이기 때문에, 해당 데이터처럼 연속형 타겟을 다루는 모델에는 적합하지 않다. 이러한 회귀 모델은 MSE, RMSE, MAE(Mean Absolute Error) 등의 지표를 사용하는 것이 적합하다.
MSE, RMSE, MAE는 모델 성능을 평가하는 데 사용되는 주요 지표입니다. 각각의 지표는 예측값과 실제값 간의 오차를 측정하는 방법이 다릅니다. 아래에서 각 지표에 대해 설명드리겠습니다.
1. MSE (Mean Squared Error, 평균 제곱 오차)
- 정의: MSE는 예측값과 실제값 간의 차이를 제곱하여 평균한 값입니다.
- 특징:
- MSE는 큰 오차에 더 큰 가중치를 두므로, 큰 오류가 발생할 경우 MSE 값이 크게 증가합니다.
- 값이 작을수록 모델의 예측이 실제값에 가까움을 나타냅니다.
2. RMSE (Root Mean Squared Error, 평균 제곱근 오차)
- 정의: RMSE는 MSE의 제곱근입니다.
- 특징:
- RMSE는 원래 데이터와 동일한 단위를 가지므로 해석이 직관적입니다.
- MSE와 마찬가지로 큰 오차에 민감합니다.
3. MAE (Mean Absolute Error, 평균 절대 오차)
- 정의: MAE는 예측값과 실제값 간의 차이의 절댓값을 평균한 값입니다.
- 특징:
- MAE는 모든 오차에 대해 동일한 가중치를 부여하므로, 큰 오차에 덜 민감합니다.
- 값이 작을수록 모델의 예측이 실제값에 가까움을 나타냅니다.
요약
- MSE: 예측 오차의 제곱 평균으로, 큰 오차에 민감함.
- RMSE: MSE의 제곱근으로, 원래 데이터 단위로 해석 가능.
- MAE: 예측 오차의 절대값 평균으로, 모든 오차에 동일한 가중치를 부여함.
이 세 가지 지표는 각각의 특성에 따라 모델의 성능을 다양한 측면에서 평가하는 데 유용합니다. 추가적인 질문이나 특정한 상황에 대한 설명이 필요하시면 말씀해 주세요!
3번
iris 데이터 DecisionTree로 분류하기
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, shuffle=True)
dt_model = DecisionTreeClassifier(random_state=42)
dt_model.fit(X_train, y_train)
y_pred = dt_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Decision Tree Accuracy: {accuracy:.2f}")
Decision Tree Accuracy: 1.00
해당 데이터 세트의 패턴을 완벽하게 학습했다는 의미이다.
이는 실제로 올바르게 학습된 것일 수도 있으나 데이터의 패턴 해석 난이도가 낮을 수도 있고, 과적합의 가능성도 존재한다.
4번
타이타닉 데이터 불러오기 및 전처리하기
기본 데이터의 특성 중 1번) 수치형 데이터 2번 비수치형 데이터로 나누어 저장하고 학습 데이터와 테스트 데이터로 구분하기
import pandas as pd
url = "https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
titanic = pd.read_csv(url)
print(titanic.head())
titanic.describe(include= 'all')<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
나이나 cabin 값의 경우 null 값이 많기 때문에 전처리가 필요하다.
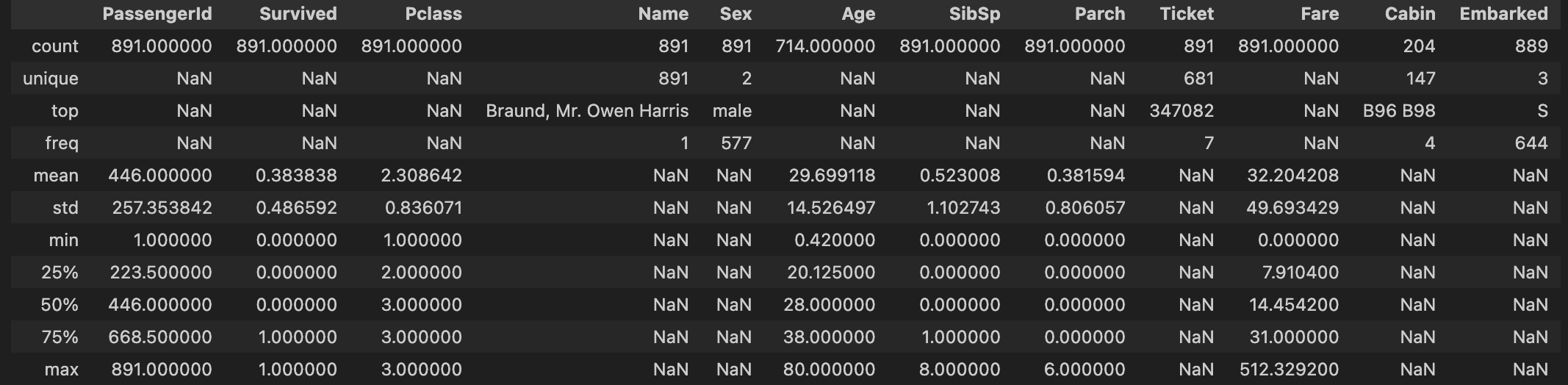
수치형 데이터는 나이, 형제, 부모, 요금 정도이다. Pclass도 가능하다.
수치형 데이터 전처리
numeric_features = ['Age', 'SibSp', 'Parch', 'Fare']
titanic_numeric = titanic[numeric_features]
titanic_numeric['Age'].fillna(titanic_numeric['Age'].mean(), inplace=True)
titanic_numeric.to_csv('titanic_numeric.csv', index=False)
print(titanic_numeric.head())
이 과정에서 강의에 나온 것처럼 SibSp, Parch 컬럼 즉 형제와 부모의 수를 더하여 Family 컬럼으로 결합하는 작업을 진행했지만 상기했듯 자료가 다 날아가버려서 그냥 데이터에 있는 대로 전처리를 굳이 하지 않았다.
그리고 나이의 경우 결측치가 너무 많기 때문에 평균 값을 결측치에 대치하였다.
평균 값을 대체하는 것은 무난하지만 항상 좋은 결과가 있는 것은 아닌데,
특성들의 pairplot을 그려보고 histogram을 그려보니 정규분포를 따르는 것으로 보여
평균 값으로 대체했다.
* inplace=True 옵션을 사용하여 원본 데이터프레임을 직접 수정할 수 있다
비수치형 데이터 전처리
categorical_features = ['Pclass', 'Sex', 'Embarked']
titanic_categorical = titanic[categorical_features]
titanic_categorical['Sex'] = titanic_categorical['Sex'].map({'male': 0, 'female': 1})
titanic_categorical['Embarked'].fillna('S', inplace=True)
titanic_categorical['Embarked'] = titanic_categorical['Embarked'].map({'C': 0, 'Q': 1, 'S': 2})
titanic_categorical.to_csv('titanic_categorical.csv', index=False)
print(titanic_categorical.head())
- 'Sex' 열의 값을 숫자로 변환합니다. 남성은 0으로, 여성은 1로 매핑합니다. 이를 통해 모델이 범주형 데이터를 이해할 수 있도록 합니다.
- 'Embarked' 열의 결측치를 'S'로 대체합니다. 이는 'S'가 가장 많이 발생한 탑승 항구이기 때문에 일반적인 접근법으로 사용됩니다.
- 이후 'Embarked' 열의 값을 숫자로 변환합니다. 'C'는 0, 'Q'는 1, 'S'는 2로 매핑하여 모델이 이 데이터를 이해할 수 있도록 합니다.
Pclass의 경우 이미 0-3의 숫자로 표현되어 있기에 따로 숫자로 변환하는 과정은 넣지 않았다.
위에 선택한 방법 0,1,2의 경우 0보다는 2가 가중치가 크기 때문에 결과가 변질될 수 있다. 따라서 ONE-HOT Encoding 작업을 할 수도 있다.
원-핫 인코딩(One-Hot Encoding)은 범주형 데이터를 숫자형 데이터로 변환하는 방법 중 하나로, 각 범주를 이진 벡터로 표현하는 기법입니다. 이 방식은 머신러닝 모델이 범주형 특성을 효과적으로 처리할 수 있도록 도와줍니다.
원-핫 인코딩의 작동 방식
- 범주형 변수 선택: 범주형 데이터를 가진 변수(예: 성별, 지역, 색상 등)를 선택합니다.
- 고유한 범주 식별: 선택한 변수에서 고유한 범주를 식별합니다. 예를 들어, '색상'이라는 변수가 '빨강', '파랑', '초록' 세 가지 값을 가질 수 있다고 가정합니다.
- 이진 벡터 생성: 각 범주에 대해 이진 벡터를 생성합니다. 각 범주에 대해 고유한 인덱스를 부여하고, 해당 인덱스에 1을 설정하고 나머지 인덱스는 0으로 설정합니다. 예를 들어:
- 빨강: [1, 0, 0]
- 파랑: [0, 1, 0]
- 초록: [0, 0, 1]
- 데이터프레임에 추가: 원-핫 인코딩된 결과는 원래 데이터프레임에 새로운 열로 추가됩니다. 원래의 범주형 변수는 삭제할 수 있습니다.
장점
- 모델 성능 향상: 원-핫 인코딩은 머신러닝 모델이 범주형 데이터의 순서를 잘못 해석하는 것을 방지합니다. 범주형 데이터가 숫자로 변환될 때, 모델이 이들 사이의 관계를 잘못 이해할 수 있기 때문입니다.
- 다양한 알고리즘에 적합: 대부분의 머신러닝 알고리즘에서 원-핫 인코딩된 데이터를 효과적으로 처리할 수 있습니다.
단점
- 차원 증가: 범주가 많을 경우, 원-핫 인코딩으로 인해 데이터의 차원이 급격히 증가할 수 있습니다. 이는 메모리 사용량과 계산 비용을 증가시킬 수 있습니다.
- 희소 행렬: 많은 범주가 있을 때 0으로 채워진 값이 많아져 희소 행렬이 생성됩니다. 이는 처리 속도에 영향을 줄 수 있습니다.
결론
원-핫 인코딩은 범주형 데이터를 숫자형 데이터로 변환하는 간단하고 효과적인 방법으로, 머신러닝 모델의 성능 향상에 기여합니다. 그러나 차원의 저주와 같은 단점도 있기 때문에 데이터의 특성에 따라 적절하게 사용해야 합니다.
두 데이터를 테스트 / 트레인 데이터로 분리
X_numeric_train, X_numeric_test = train_test_split(titanic_numeric, test_size=0.3, random_state=42)
X_categorical_train, X_categorical_test = train_test_split(titanic_categorical, test_size=0.3, random_state=42)
print("Numeric Train Shape:", X_numeric_train.shape)
print("Numeric Test Shape:", X_numeric_test.shape)
print("Categorical Train Shape:", X_categorical_train.shape)
print("Categorical Test Shape:", X_categorical_test.shape)
Numeric Train Shape: (623, 4)
Numeric Test Shape: (268, 4)
Categorical Train Shape: (623, 3)
Categorical Test Shape: (268, 3)
5번
sklearn 라이브러리의 랜덤포레스트 모델을 활용해 1번 데이터와 2번 데이터 학습하기
테스트 데이터에 대한 성능을 Precision, Recall로 측정 후 성능 비교하기
F1 score 직접 계산하고 정밀도와 재현성 과의 관계 정리하기
챌린지 - 랜덤포레스트 생성 시 하이퍼파라미터 조작해보기
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import precision_score, recall_score
target = titanic['Survived']
X_numeric_train, X_numeric_test, y_train, y_test = train_test_split(titanic_numeric, target, test_size=0.3, random_state=42)
X_categorical_train, X_categorical_test, y_train2, y_test2 = train_test_split(titanic_categorical, target, test_size=0.3, random_state=42)
rf_numeric = RandomForestClassifier(random_state=42)
rf_numeric.fit(X_numeric_train, y_train)
y_pred_numeric = rf_numeric.predict(X_numeric_test)
rf_categorical = RandomForestClassifier(random_state=42)
rf_categorical.fit(X_categorical_train, y_train2)
y_pred_categorical = rf_categorical.predict(X_categorical_test)
precision_numeric = precision_score(y_test, y_pred_numeric)
recall_numeric = recall_score(y_test, y_pred_numeric)
f1_score_numeric = 2 * (precision_numeric * recall_numeric) / (precision_numeric + recall_numeric)
print("수치형 데이터 성능:")
print(f"Precision: {precision_numeric:.2f}")
print(f"Recall: {recall_numeric:.2f}")
print(f"F1 Score: {f1_score_numeric:.2f}")
precision_categorical = precision_score(y_test2, y_pred_categorical)
recall_categorical = recall_score(y_test2, y_pred_categorical)
f1_score_categorical = 2 * (precision_categorical * recall_categorical) / (precision_categorical + recall_categorical)
print("비수치형 데이터 성능:")
print(f"Precision: {precision_categorical:.2f}")
print(f"Recall: {recall_categorical:.2f}")
print(f"F1 Score: {f1_score_categorical:.2f}")
수치형 데이터 성능:
Precision: 0.59
Recall: 0.53
F1 Score: 0.56
비수치형 데이터 성능:
Precision: 0.86
Recall: 0.61
F1 Score: 0.72
수치형 데이터보다 비수치형 데이터의 성능이 더 높은 것으로 보인다.
수치형 데이터의 경우 정밀도와 재현율이 50%대인 것으로 보아 위양성이 많은 모델이고 찍는 것만 못하기 때문에 적절한 모델이 아니다. 따라서 더 나은 성능을 위해 전처리를 다르게 시도해보거나 다른 모델을 활용해야한다.
[머신러닝 with Python] 선형회귀(Linear Regression) / 당뇨병(Diabetes) 데이터 활용 / EDA 시각화 포함
이번에는 지난 포스팅에 이어서 선형회귀(Linear Regression)에 대해서 알아보겠습니다. 지난 포스팅에서는 선형회귀의 기본 개념과 예제 데이터를 만들어 파이썬 코딩을 통해, 모델을 구현해보고
jaylala.tistory.com
머신러닝 with Python] 선형회귀(Linear Regression) / 당뇨병(Diabetes) 데이터 활용 / EDA 시각화 포함
https://brunch.co.kr/@parkkyunga/86
08화 8. 다항회귀 (Polynomial Reg.)
선형회귀 알고리즘에서는 무작정 피처를 많이 넣는 게 좋은 게 아니고 서로 상관관계가 높은 컬럼들은 제거하는 게 낫다는 다중공선성에 대해 알아보았다. 다른 피처 엔지니어링 없이 모든 컬
brunch.co.kr
다항회귀
https://sumniya.tistory.com/26
분류성능평가지표 - Precision(정밀도), Recall(재현율) and Accuracy(정확도)
기계학습에서 모델이나 패턴의 분류 성능 평가에 사용되는 지표들을 다루겠습니다. 어느 모델이든 간에 발전을 위한 feedback은 현재 모델의 performance를 올바르게 평가하는 것에서부터 시작합니
sumniya.tistory.com
https://yhyun225.tistory.com/11
회귀 (3) - 당뇨병 환자 데이터(diabetes)와 다중 선형 회귀(Multi Regression Model)
사이킷런(scikit-learn)은 파이썬에서 제공하는 머신러닝 라이브러리입니다. 사이킷런에는 머신러닝을 익힐 수 있는 여러 툴들이 존재합니다. 이번 포스팅에서는 사이킷런에서 제공하는 당뇨병(dia
yhyun225.tistory.com
https://hyjykelly.tistory.com/44
[모델 평가] 훈련데이터셋 나누기 (feat.train_test_split())
이번 포스팅에서는 머신러닝/딥러닝 모델의 성능평가를 위해 훈련데이터셋을 나누는 이유와 방법에 대해 알아본다. WHY ? 인공지능 모델을 구축하면 실제 상황에 적용하기 전에 성능평가를 진행
hyjykelly.tistory.com
[ML] 분류 성능 지표: Precision(정밀도), Recall(재현율), F1-score
분류 모델이 얼마나 잘 학습되었는지에 대한 성능 지표는 Accuracy (정확도), Precision (정밀도), Recall (재현율) 등이 있습니다. 각각의 성능 지표 전에 confusion matrix 먼저 알아보도록 하겠습니다. 1) Con
ai-com.tistory.com