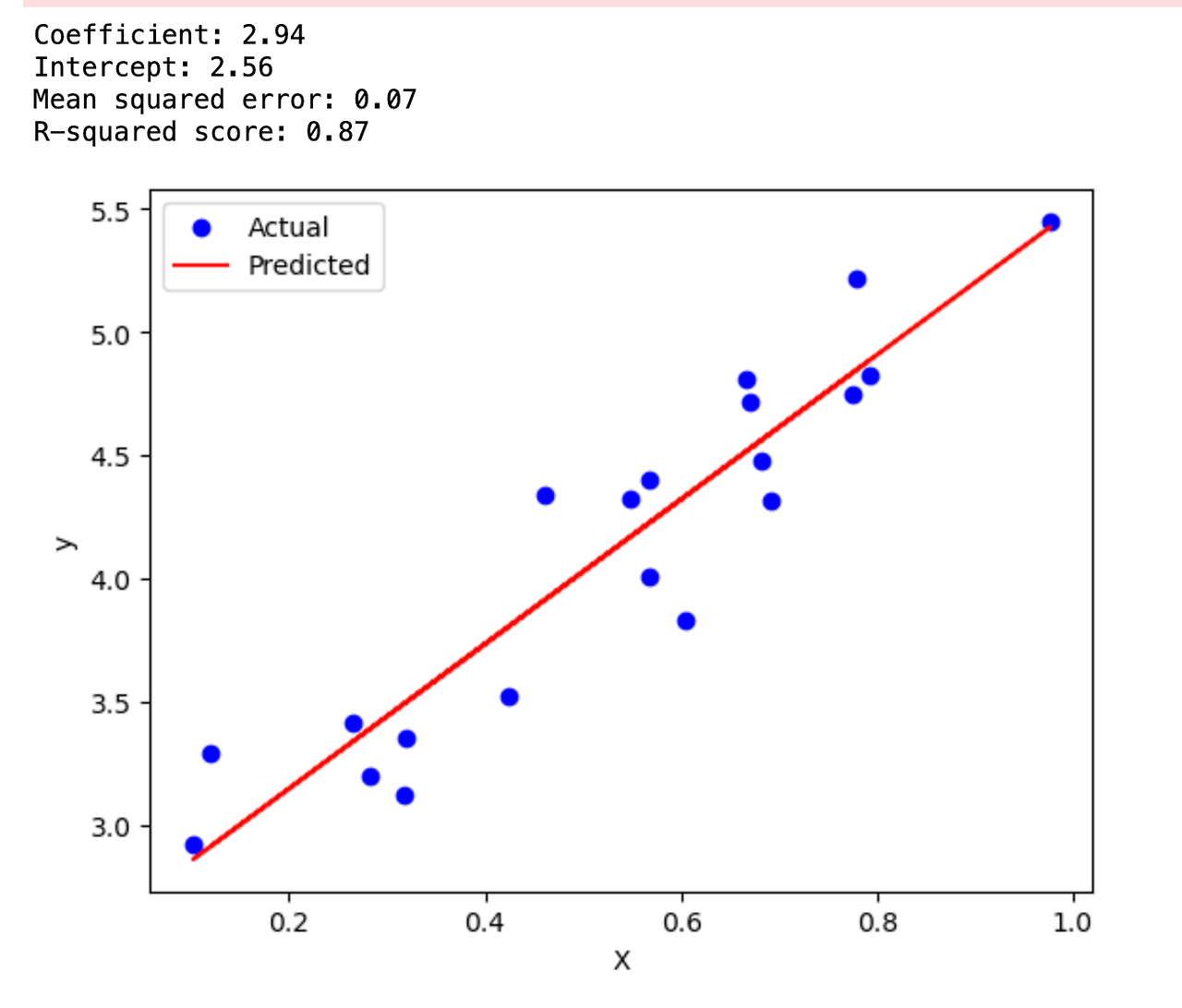
- 여러분은 Spotify에 재직하는 머신러닝 분야에 특화된 데이터 분석가입니다.고객이 선호하는 곡과 유사한 곡을 연이어 재생할 수 있는 ‘음악 추천 서비스’를 기획하고자 합니다.- Spotify는 서비스 개선 목적 외에도 연구나 자유로운 분석을 위해 API 및 데이터셋을 공개했습니다.이를 통해 수많은 곡에 대한 특성을 분석하며 분류를 시도해 볼 수 있습니다.- 데이터 시각화와 탐색적 데이터 분석(EDA)을 통해 데이터를 이해하고,추천 시스템을 구성할 수 있도록 기초 정보를 제공하는 음원 군집화의 방향성에 대해 고민이 필요합니다.선호하는 노래와 ‘비슷한’ 곡이라는 정의를 어떻게 내릴 수 있을까요?- 곡의 구성요소 별로 군집화- 클러스터링 선택에 도움이 될 수 있는 데이터셋의 특성을 파악하고 다양한 모델을..